Bài 1: Giới thiệu về Generative AI và LLMs
Mục tiêu của bài học hôm nay gồm:
- Generative AI là gì và LLMs hoạt động như thế nào?
- Cách bạn có thể tận dụng các mô hình ngôn ngữ lớn cho các trường hợp sử dụng khác nhau
Generative AI là gì?
Generative AI là trí tuệ nhân tạo có khả năng tạo ra văn bản, hình ảnh và các loại nội dung khác. Điều khiến nó trở thành một công nghệ tuyệt vời là nó dân chủ hóa AI, bất kỳ ai cũng có thể sử dụng nó chỉ với một câu lệnh bằng văn bản, một câu được viết bằng ngôn ngữ tự nhiên. Bạn không cần phải học một ngôn ngữ như Java hay SQL để đạt được điều gì đó đáng giá, tất cả những gì bạn cần là sử dụng ngôn ngữ của mình, nêu rõ những gì bạn muốn và đưa ra gợi ý từ mô hình AI. Ứng dụng và tác động của việc này là rất lớn, bạn viết hoặc hiểu báo cáo, viết ứng dụng, v.v., tất cả chỉ trong vài giây.
Vậy làm sao để có được Generative AI như hiện tại? Nó xuất phát từ sự phải triển của AI nói chung, AI được đề cập lần đầu vào những năm 60s của thế kỷ trước. Những nguyên mẫu đầu tiên của AI bao gồm các chatbot đánh máy, dựa vào một cơ sở kiến thức được trích xuất từ một nhóm chuyên gia và được biểu diễn trong máy tính. Các câu trả lời trong cơ sở kiến thức được kích hoạt bởi các từ khóa xuất hiện trong văn bản nhập vào. Tuy nhiên, sớm trở nên rõ ràng rằng cách tiếp cận như vậy, sử dụng các chatbot đánh máy, không mở rộng tốt.
Một cách tiếp cận thống kê đối với AI: Học Máy
Bước ngoặt đến vào những năm 90, với việc áp dụng cách tiếp cận thống kê vào phân tích văn bản. Điều này dẫn đến sự phát triển của các thuật toán mới - được biết đến với tên gọi học máy - có khả năng học các mẫu từ dữ liệu, mà không cần được lập trình cụ thể. Cách tiếp cận này cho phép máy tính mô phỏng sự hiểu ngôn ngữ của con người: một mô hình thống kê được huấn luyện trên cặp văn bản - gán nhãn, cho phép mô hình phân loại văn bản đầu vào không rõ ràng với một nhãn được định nghĩa trước đại diện cho ý định của thông điệp.
Mạng lưới thần kinh và trợ lý ảo hiện đại
Trong thời gian gần đây, sự phát triển công nghệ của phần cứng, có khả năng xử lý lượng dữ liệu lớn hơn và tính toán phức tạp hơn, đã khuyến khích nghiên cứu trong lĩnh vực AI, dẫn đến sự phát triển của các thuật toán học máy tiên tiến – được gọi là mạng lưới thần kinh hoặc thuật toán học sâu.
Mạng thần kinh (và đặc biệt là Mạng thần kinh hồi quy – RNN) đã tăng cường đáng kể việc xử lý ngôn ngữ tự nhiên, cho phép thể hiện ý nghĩa của văn bản theo cách có ý nghĩa hơn, đánh giá ngữ cảnh của một từ trong câu.
Đây là công nghệ hỗ trợ các trợ lý ảo ra đời trong thập kỷ đầu tiên của thế kỷ mới, rất thành thạo trong việc diễn giải ngôn ngữ con người, xác định nhu cầu và thực hiện hành động để thỏa mãn nhu cầu đó – như trả lời bằng một tập lệnh định sẵn hoặc sử dụng một dịch vụ của bên thứ 3.
Generative AI ngày nay
Và đó là cách chúng ta đến với Generative AI ngày nay, có thể được coi là một tập hợp con của deep learning.
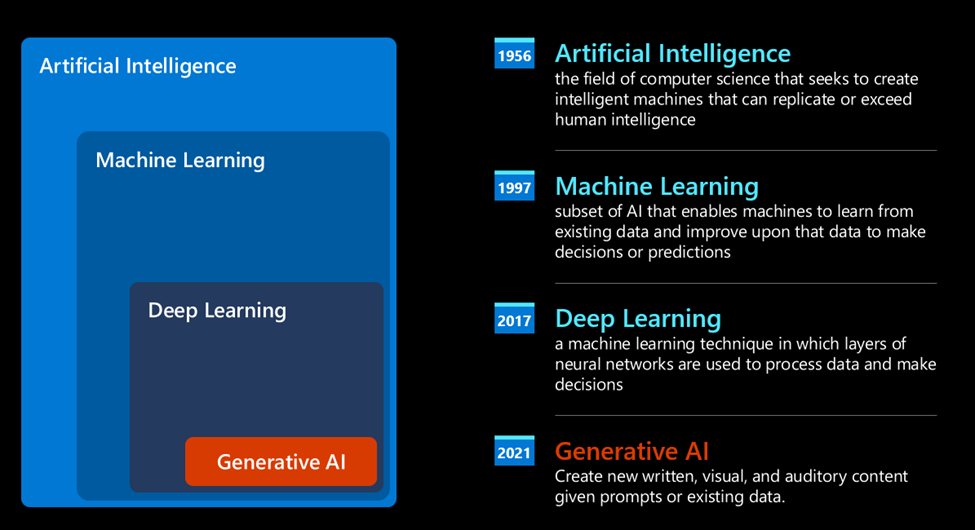
Sau nhiều thập kỷ nghiên cứu trong lĩnh vực AI, một kiến trúc mô hình mới – được gọi là Transformer – đã vượt qua giới hạn của mạng thần kinh hồi quy, có khả năng xử lý những chuỗi văn bản dài hơn nhiều làm đầu vào. Transformer dựa trên cơ chế "chú ý" - attention, cho phép mô hình gán trọng số khác nhau cho các đầu vào mà nó nhận được, 'chú ý nhiều hơn' đến nơi tập trung thông tin quan trọng nhất, bất kể thứ tự của chúng trong chuỗi văn bản.
Mô hình ngôn ngữ lớn - Large Language Models (LLM) là gì?
Các mô hình ngôn ngữ lớn (LLM) là các mô hình học sâu rất lớn, được đào tạo trước dựa trên một lượng dữ liệu khổng lồ. Bộ chuyển hóa cơ bản là tập hợp các mạng nơ-ron có một bộ mã hóa và một bộ giải mã với khả năng tự tập trung. Bộ mã hóa và bộ giải mã trích xuất ý nghĩa từ một chuỗi văn bản và hiểu mối quan hệ giữa các từ và cụm từ trong đó. Nếu bạn muốn tìm hiểu sâu hơn về LLM thì có thể xem tại đây: Mô hình ngôn ngữ lớn là gì? – Giải thích về AI LLM – AWS (amazon.com)
Mô hình ngôn ngữ lớn hoạt động như thế nào?
- Dự đoán các tokens đầu ra: Với n tokens nhập vào (với giá trị tối đa của n thay đổi tùy thuộc vào từng mô hình), mô hình có khả năng dự đoán token đầu ra. Token này sau đó được tích hợp vào đầu vào của lần lặp tiếp theo, theo một mô hình mở rộng, tạo điều kiện cho trải nghiệm người dùng tốt hơn khi nhận được một (hoặc nhiều) câu trả lời như mong muốn. Điều này giải thích tại sao, nếu bạn đã từng tương tác với ChatGPT, có thể bạn đã nhận thấy rằng đôi khi nó dừng giữa một câu.
- Quá trình lựa chọn, phân phối xác suất: Mô hình chọn token đầu ra dựa trên xác suất của nó xuất hiện sau chuỗi văn bản hiện tại. Điều này xảy ra vì mô hình dự đoán một phân phối xác suất trên tất cả các 'token tiếp theo' có khả năng xảy ra, được tính toán dựa trên quá trình huấn luyện của nó. Tuy nhiên, không phải lúc nào token có xác suất cao nhất cũng được chọn từ phân phối kết quả. Một mức độ ngẫu nhiên được thêm vào lựa chọn này, theo một cách mà mô hình hoạt động theo cách không xác định - chúng ta không nhận được đầu ra chính xác như nhau cho cùng một đầu vào. Mức độ ngẫu nhiên này được thêm vào để mô phỏng quá trình tư duy sáng tạo và có thể được điều chỉnh bằng cách sử dụng một tham số của mô hình gọi là temperature - nhiệt độ. Đây chính là phương pháp học không giám sát trong Học máy. Nếu bạn muốn tìm hiểu kỹ hơn hãy tìm chúng trên internet.
Nói cho dễ hiểu thì là một LLM học các từ, cũng như các mối quan hệ giữa chúng và các khái niệm đằng sau chúng. Ví dụ, nó có thể học cách phân biệt hai nghĩa của từ “bark” dựa trên ngữ cảnh của nó dựa trên dữ liệu huấn luyện nó, dữ liệu càng lớn và chính xác thì kết quả càng chính xác. Các LLM cũng có thể được tùy chỉnh cho các trường hợp sử dụng cụ thể, bao gồm thông qua các kỹ thuật như fine-tuning hoặc prompt-tuning, đây là quá trình cung cấp cho mô hình các bit dữ liệu nhỏ để tập trung vào, nhằm huấn luyện mô hình cho một ứng dụng cụ thể.
Làm thế nào để tận dụng Mô hình ngôn ngữ lớn?
Bây giờ khi chúng ta đã hiểu rõ hơn về cách một mô hình ngôn ngữ lớn hoạt động, hãy xem một số ví dụ thực tế về các nhiệm vụ phổ biến mà chúng có thể thực hiện khá tốt. Chúng ta nói rằng khả năng chính của một Mô hình Ngôn ngữ Lớn là tạo văn bản từ đầu, bắt đầu từ một đầu vào văn bản, được viết bằng ngôn ngữ tự nhiên.
Nhưng loại đầu vào và đầu ra nào? Đầu vào của một mô hình ngôn ngữ lớn được biết đến là "prompt," trong khi đầu ra được biết đến là "completion," thuật ngữ này đề cập đến cơ chế của mô hình tạo mã thông báo tiếp theo để hoàn thành đầu vào hiện tại. Chúng ta sẽ đào sâu vào việc làm thế nào một prompt được thiết kế để đạt được hiệu suất tốt nhất từ mô hình của chúng ta. Nhưng tạm thời, hãy chỉ nói rằng một prompt có thể bao gồm:
- Một hướng dẫn xác định loại đầu ra mà chúng ta mong đợi từ mô hình. Hướng dẫn này đôi khi có thể chứa một số ví dụ hoặc dữ liệu bổ sung.
- Tóm tắt một bài viết, sách, đánh giá sản phẩm và nhiều nhiệm vụ khác, cùng với trích xuất thông tin từ dữ liệu không cấu trúc.
- Tạo ý tưởng sáng tạo và thiết kế cho một bài viết, một bài luận, một bài tập, hoặc nhiều nhiệm vụ khác.


- Một câu hỏi được đặt dưới dạng cuộc trò chuyện với một nhân vật có tính cách cụ thể
- Một đoạn văn bản cần hoàn thiện, ngụ ý một yêu cầu hỗ trợ viết.
- Một đoạn mã lập trình cùng với yêu cầu giải thích và viết tài liệu, hoặc một bình luận yêu cầu tạo ra một đoạn mã thực hiện một nhiệm vụ cụ thể.
Các ví dụ trên khá đơn giản và không muốn là một chứng minh toàn diện về khả năng của Mô hình Ngôn ngữ Lớn. Chúng chỉ muốn thể hiện tiềm năng của việc sử dụng trí tuệ nhân tạo sáng tạo. Mình cũng sẽ có 1 video chi tiết về nội dung này sau. Các bạn hãy chú ý đón xem nhé